热门搜索:
在爬取一些简单的(没有反爬机制的)静态网页时,一般采取的策略是:选中目标(所谓的url链接),观察结构(链接结构,网页结构),构思动手(选用什么HTML下载器,解析器等)。在爬虫过程中,都会涉及到三种利器:
HTML下载器:下载HTML网页
HTML解析器:解析出有效数据
数据存储器:将有效数据通过文件或者数据库的形式存储起来
今天,我们将利用requests库和BeautifulSoup模块来抓取中彩网页福彩3D相关的信息,并将其保存到Excel表格中。
在开始前,先分析看看目标网页的结构:
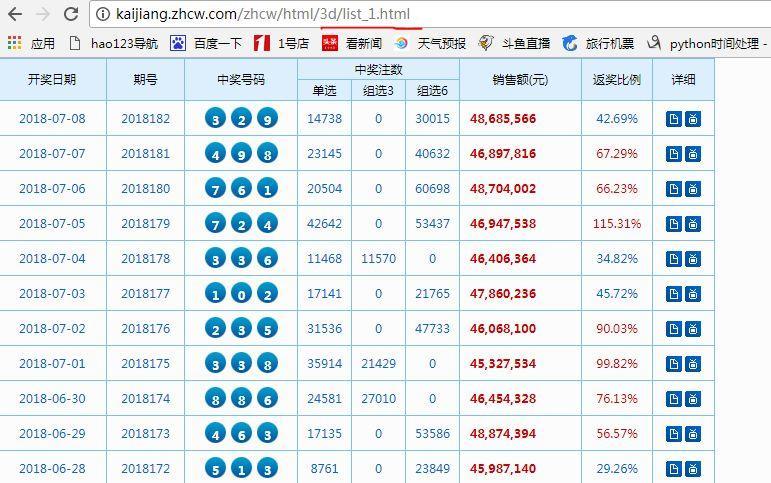
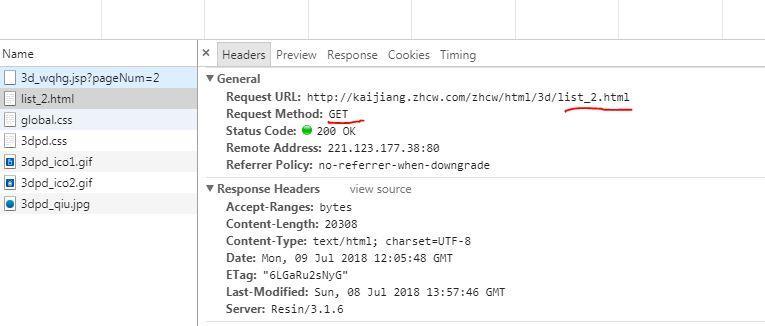
可以发现,目标网页的URL http://kaijiang.zhcw.com/zhcw/html/3d/list_2.html,每次变化一处:list_x后面的数字,其代表第几页。
然后,观察其网页结构,也很简单,可以看到一期的彩票信息对应的源代码是一个tr节点,我们可以用BeautifulSoup库来提取这里面的一些信息。
整体思路是:若要获取福彩3D创办14年以来所有的信息(一共246页),只需要分开请求246次,这样获取不同的页面之后,再利用BeautifulSoup库提取到相关信息,利用xlrd库将数据写入Excel中,就可以获取到福彩3D所有的信息,结果如下图:


(一共将近5000条数据)
详情代码如下:
import requests
from bs4 import BeautifulSoup
import xlwt
import time
#获取第一页的内容
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
#解析第一页内容,数据结构化
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
i = 0
for item in soup.select('tr')[2:-1]:
yield{
'time':item.select('td')[i].text,
'issue':item.select('td')[i+1].text,
'digits':item.select('td em')[0].text,
'ten_digits':item.select('td em')[1].text,
'hundred_digits':item.select('td em')[2].text,
'single_selection':item.select('td')[i+3].text,
'group_selection_3':item.select('td')[i+4].text,
'group_selection_6':item.select('td')[i+5].text,
'sales':item.select('td')[i+6].text,
'return_rates':item.select('td')[i+7].text
}
#将数据写入Excel表格中
def write_to_excel:
f = xlwt.Workbook
sheet1 = f.add_sheet('3D',cell_overwrite_ok=True)
row0 = ["开奖日期","期号","个位数","十位数","百位数","单数","组选3","组选6","销售额","返奖比例"]
#写入第一行
for j in range(0,len(row0)):
sheet1.write(0,j,row0[j])
#依次爬取每一页内容的每一期信息,并将其依次写入Excel
i=0
for k in range(1,247):
url = 'http://kaijiang.zhcw.com/zhcw/html/3d/list_%s.html' %(str(k))
html = get_one_page(url)
print('正在保存第%d页。'%k)
#写入每一期的信息
for item in parse_one_page(html):
sheet1.write(i+1,0,item['time'])
sheet1.write(i+1,1,item['issue'])
sheet1.write(i+1,2,item['digits'])
sheet1.write(i+1,3,item['ten_digits'])
sheet1.write(i+1,4,item['hundred_digits'])
sheet1.write(i+1,5,item['single_selection'])
sheet1.write(i+1,6,item['group_selection_3'])
sheet1.write(i+1,7,item['group_selection_6'])
sheet1.write(i+1,8,item['sales'])
sheet1.write(i+1,9,item['return_rates'])
i+=1
f.save('3D.xls')
def main:
write_to_excel
if __name__ == '__main__':
main
点击下载:3d.py
到此,关于14年的福彩3D信息都可以爬取下来,至于如何预测?下一期的彩票趋势如何?不懂也不会,接下来是否中奖,就靠你们了。彩民们,我只能帮你们到这了!
最后结尾,关于彩票预测究竟准不准?我不说太多的理论分析,我只提出两个问题:
命题1:以双色球为例,下一期双色球号码,1,2,3,4,5,6,7 和 3,4,8,11,22,29,7 这两组号码的中奖概率如何?谁高谁低还是都一样?
命题2:第二个问题更简单。假设你已经投了9次硬币,结果都是正面。现在你要投第10次,请问是正面的概率是多少?
如果你还要问我,彩票有规律可循吗?在我看来,彩票规律就是没有规律(不信,你去分析分析14年以来的所有数据),以人类的计算水平,即使有的话也计算不出来的。彩票是娱乐,是一个运气的游戏,一个人即使在彩票上赚到了钱,运气好,也不代表使用的方法就可以提高彩票中奖率。任何打着提高中奖率的期号进行的盈利行为,即使出发点是善意的,也会最终走向错误。
xx的彩票(尤其是黑彩)的实质,就是虚构一个不劳而获的人,去忽悠一群想不劳而获的人,最终养活一批真正不劳而获的人。犹如币圈一个bi样!
文末知识点摘要:Pycharm自动导入模块小技巧
周末愉快!不知道大家周末写不写代码,哈哈,反正我已经加完班回来了,今天分享一个能提高编码效率的小技巧,可能你早就在用了,也可能像我一样刚学会,还是趁热跟大家分享一下。
如果能把工具熟练运用,往往能达到事半功倍的效果,Pycharm 是很多Python开发者的首选IDE,提供各种快捷键、重构功能、调试技巧等,Python是动态语言,对于自动导入模块没有静态语言那么方便,但有了 Pycharm,还是可以很强大。
平时写代码的时候,要引用系统自带的模块或者是第三方模块,甚至是项目中的模块,有时候代码快写一整屏了,为了把一个模块导入进来,我们不得不把光标拉到文件顶部,先把模块名手动导入进来,再回到文件底部开始写代码,如此重复来回地切换,好麻烦。做开发的一个原则就是 Don’t repeat yourself,重复的劳动应该让它自动去完成。
其实,我们只需要简单两步配置就可以让Pycharm自动导入模块
第一步:Pycharm->Perferences->Editor->Auto Import
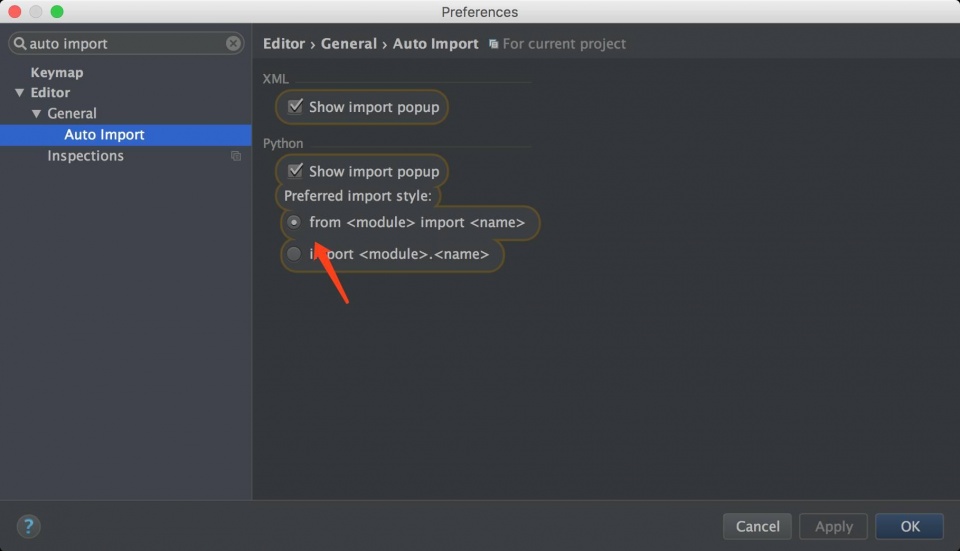
第二步:Pycharm->Perferences->Keymap
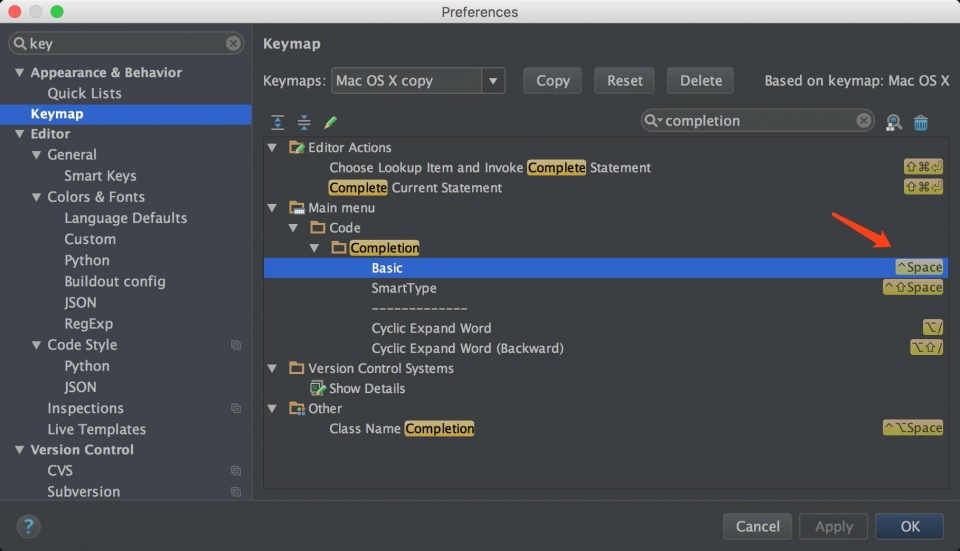
就这么简单,设置完成后,来体验一下效果。导入random 模块,按住 ctrl+空格(空格键按两下)就会自动弹出可选的模块列表,上下移动进行切换。
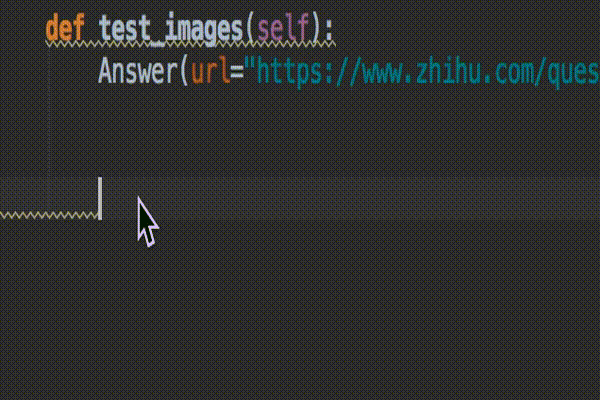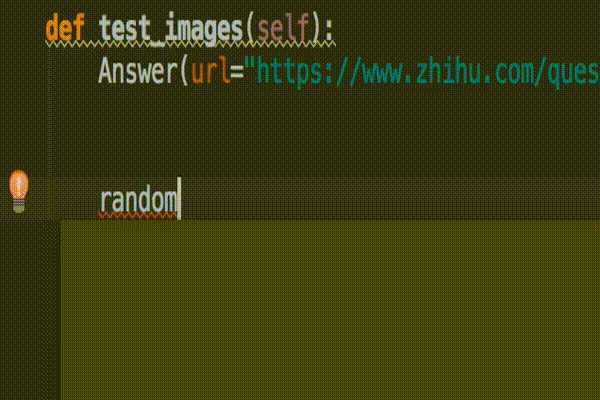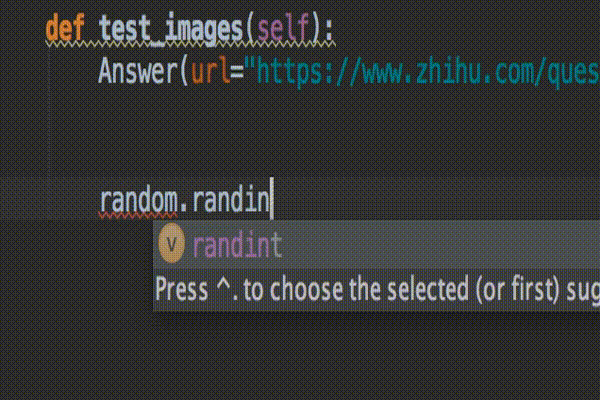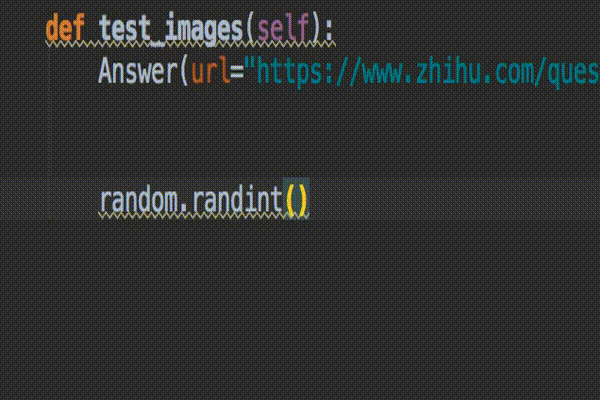
你平时有哪些高效的编程技巧?不如跟大家分享一下。
上一篇:对Python开发者的编码建议
下一篇:Python字符串处理技巧大全

QQ客服

公众号


手机版


帮助中心
