热门搜索:
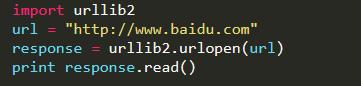
get方法
post方法
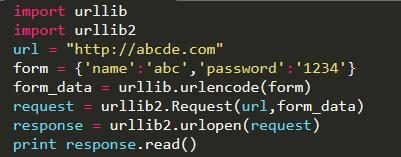
这在某些情况下比较有用,
比如IP被封了,或者比如IP访问的次数受到限制等等。


是的没错,如果想同时用代理和cookie,
那就加入proxy_support然后operner改为 ,如下:

某些网站反感爬虫的到访,于是对爬虫一律拒绝请求。
这时候我们需要伪装成浏览器,
这可以通过修改http包中的header来实现:

对于页面解析最强大的当然是正则表达式,
这个对于不同网站不同的使用者都不一样,就不用过多的说明。
其次就是解析库了,常用的有两个lxml和BeautifulSoup。
对于这两个库,我的评价是,
都是HTML/XML的处理库,Beautifulsoup纯python实现,效率低,
但是功能实用,比如能用通过结果搜索获得某个HTML节点的源码;
lxmlC语言编码,高效,支持Xpath。
碰到验证码咋办?
这里分两种情况处理:
google那种验证码,没办法。
简单的验证码:字符个数有限,只使用了简单的平移或旋转加噪音而没有扭曲的,
这种还是有可能可以处理的,一般思路是旋转的转回来,噪音去掉,
然后划分单个字符,划分好了以后再通过特征提取的方法(例如PCA)降维并生成特征库,
然后把验证码和特征库进行比较。
这个比较复杂,这里就不展开了,
具体做法请弄本相关教科书好好研究一下。
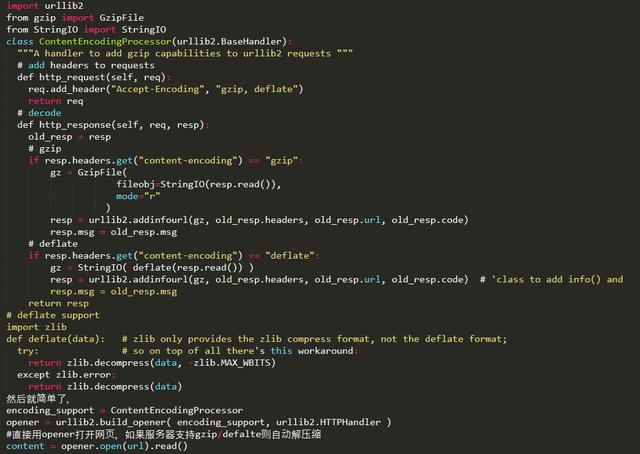
现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,
以VeryCD的主页为例,未压缩版本247K,压缩了以后45K,为原来的1/5。
这就意味着抓取速度会快5倍。
然而python的urllib/urllib2默认都不支持压缩
要返回压缩格式,必须在request的header里面写明’accept-encoding’,
然后读取response后更要检查header查看是否有’content-encoding’一项来判断是否需要解码,很繁琐琐碎。
如何让urllib2自动支持gzip, defalte呢?
其实可以继承BaseHanlder类,
然后build_opener的方式来处理:
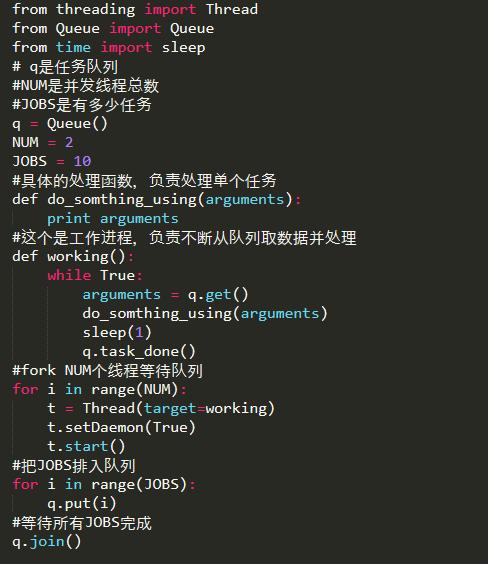
单线程太慢的话,就需要多线程了,
这里给个简单的线程池模板 这个程序只是简单地打印了1-10,
但是可以看出是并发的。
虽然说Python的多线程很鸡肋
但是对于爬虫这种网络频繁型,
还是能一定程度提高效率的。
阅读Python编写的代码感觉像在阅读英语一样,这让使用者可以专注于解决问题而不是去搞明白语言本身。
Python虽然是基于C语言编写,但是摒弃了C中复杂的指针,使其变得简明易学。
并且作为开源软件,Python允许对代码进行阅读,拷贝甚至改进。
这些性能成就了Python的高效率,有“人生苦短,我用Python”之说,是一种十分精彩又强大的语言。
总而言之,开始学Python一定要注意这4点:

QQ客服

公众号


手机版


帮助中心
